Microsoft SQL Server is a relational database management system developed by Microsoft. As a database server, it is a software product with the primary function of storing and retrieving data as requested by other software applications.
To create a connection to the Microsoft SQL Data Source. Right-click on the Data Sources group, then click “Microsoft”, and then select “SQL Database”.
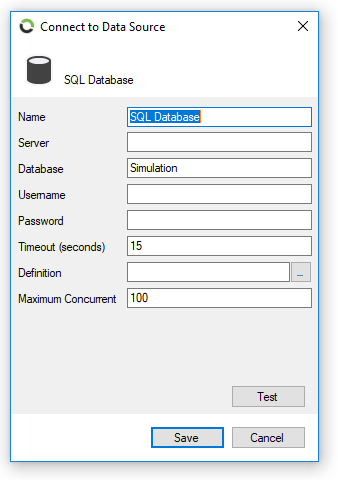
To successfully retrieve data from a Microsoft SQL Historian data source, the following properties need to be set.
|
Name to identify the data source. |
|
Location of the SQL Database (Server Name or IP Address). |
|
Name of the Database, default simulation. |
|
SQL authentication Username. If left blank, Windows authentication will be used. |
|
SQL authentication Password. If left blank, Windows authentication will be used. |
|
Timeout for SQL queries. The default is 15 seconds. |
|
Definition settings to create a custom namespace as per your database schema. |
|
Maximum pooling count size for the SQL connection. The default is 100. |
Transactional Data and Flow
Flow is very good at understanding the way tag historians store their data. This makes configuring Events and Measures really easy. However, when you connect Flow to a Microsoft SQL Data Source, Flow will not "understand" the structure of your data, making it a little tricky to configure.
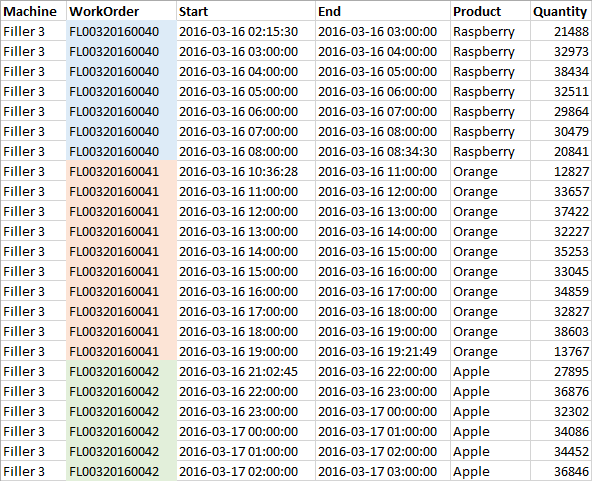
Here are a few guidelines and an example to get you started. In this example, we have a single "Quantity" value recorded every hour for a specific "Work Order" and corresponding "Product". It is possible that more than one record could be inserted for a single hour during a "Work Order" change over. These records are stored in a SQL table called "ProdData". We will be creating an Hourly measure.
Measure Values
When retrieving data for a Measure's value, and you configure that Flow does not perform any aggregation (by setting the Aggregation property to "None") your SQL script must return a single record for the time period being queried, for example:
select sum(Quantity) as Value, 192 as Quality from ProdData
But this would sum all the records in the table. We need to give Flow more information about the time periods to query. At any point in time, Flow knows what time period it is busy processing for our measure. We can use Flow [Placeholders] to augment this SQL query:
select sum(Quantity) as Value, 192 as Quality from ProdData where Start >= [PeriodStart] and End < [PeriodEnd]
Flow will now sum the records for the hour that is being processed.
For this example, we may want to filter our SQL query for the "Filler 3" Machine only.
select sum(Quantity) as Value, 192 as Quality from ProdData where Start >= [PeriodStart] and End < [PeriodEnd] and Machine = 'Filler 3'
One last thing ... because this query makes use of a SQL aggregation method (i.e. "sum"), it would return a NULL value if there were no records for a specific hour. Flow will handle the NULL values, but it may be more elegant for the SQL query to return 0 rather than NULL:
select isnull(sum(Quantity), 0) as Value, 192 as Quality from ProdData where Start >= [PeriodStart] and End < [PeriodEnd] and Machine = 'Filler 3'
When querying transactional data, you may apply any of Flow's aggregation methods to the result set. If you do so, then you must include a Timestamp with the returned data. So, the above query would need to be adapted to something like:
select Start as Timestamp, isnull(sum(Quantity), 0) as Value, 192 as Quality from ProdData where Start >= [PeriodStart] and End < [PeriodEnd] and Machine = 'Filler 3'
group by Start
Note the additional named column "Timestamp" which is required when you set the Aggregation property to anything other than none.
You may also bring back the boundary value, which is required for certain aggregations, by adding a named column "Boundary" to the result set, and then indicating where a row in the result set is a boundary or not (with a 1 or 0 flag).
An example of this is shown below:
select Timestamp, Value, Quality, Boundary from (
select Start as Timestamp, isnull(sum(Quantity), 0) as Value, 192 as Quality, 0 as Boundary
from ProdData
where Start >= [PeriodStart]
and EndTime <= [PeriodEnd]
and Machine = 'Filler 3'
group by Start
union
select top 1 Start as Timestamp, isnull(sum(Quantity), 0) as Value, 192 as Quality, 1 as Boundary
from ProdData
where Start < [PeriodStart]
group by Start
order by Start desc) a
order by Timestamp
Event Triggers
When retrieving data for an Event's triggers, your SQL script must return zero or more "Timestamps", e.g.
select Start from ProdData
But this would return the "Start" value for all the records in the table. We need to give Flow more information about the time span to query. Like the measure value's query, we can use Flow [Placeholders] to augment this query:
select Start from ProdData where Start >= [PeriodStart] and End < [PeriodEnd] and Machine = 'Filler 3'
Flow will now return all the "Starts" found during the last period being processed.
For the example data above, this would result in a new Event Period being created every hour at least. What we actually want is a new Event Period every time the "Work Order" changes. Let's change our SQL query to a "group by" on the "Work Order" column and select the minimum "Start":
select min(Start) from ProdData where Machine = 'Filler 3' group by WorkOrder having min(Start) >= [PeriodStart] and min(Start) < [PeriodEnd]
Flow will create a new Event Period every time the Work Order changes.
If you require an End Trigger, use the following SQL query:
select max(End) from ProdData where Machine = 'Filler 3' group by WorkOrder having max(End) >= [PeriodStart] and max(End) < [PeriodEnd]
Event Attribute Segments
When retrieving data for an Event Attribute's Segment (i.e. context), your SQL script must return a single value. Flow will convert this value into a string, or, if your segment is linked to an enumeration, it will perform the ordinal lookup and return the resultant string.
Like the measure value and event trigger queries, we can use a Flow [Placeholder] to retrieve an Event Attribute Segment's value:
select Product from ProdData where Machine = 'Filler 3' and Start = [TimeStamp]
Flow defaults the [TimeStamp] placeholder to 0 seconds after the Event Period has started. This can be changed by modifying the attribute segment's "Retrieve Point".
For the example data above, let's create a "Work Order" Attribute and a "Product" Attribute:
select WorkOrder from ProdData where Machine = 'Filler 3' and Start = [TimeStamp]
select Product from ProdData where Machine = 'Filler 3' and Start = [TimeStamp]
In this example, the Measure Values, Event Triggers and Event Attribute Segment values all came from the same SQL table. Something to consider is that each of these Flow retrievals could come from different data sources.