Before retrieving data into your Flow System, you need to connect it to one or more Data Sources. Flow has a number of standard Data Source connectors that can be used to collect data from typical sources one might encounter at a production facility (e.g. databases, tag historians, etc.)
Flow has been designed using a "modular" (or "plugin") architecture. Data Source connectors are actually "modules" provided as part of your Flow installation.
Data Sources are configured in the “Data Integration” tab at the bottom of the Flow Config tool, on the right-hand side.
Data Sources
To configure a new Data Source, right-click on the “Data Sources” item and select “New”. By default, a new Flow System will have the following Data Sources available:
| Flow Software |
|
| Canary |
|
| Inductive Automation |
|
| Microsoft |
|
| Oracle |
|
| Postgres |
|
| Wonderware |
|
| Cloud |
|
| OPC |
|
Namespace
Once a Data Source connection has been added to the Flow System, selecting it will populate its Namespace. The Namespace is provided by the Data Source (e.g. a tag historian typically provides a tree structure containing its tags, or a SQL database provides a catalog of all its tables and columns). The Namespace allows you to easily navigate to the tags you are interested in retrieving into your Flow System.
Search for specific tags by clicking on the "magnifying glass" icon within Namespace panel.
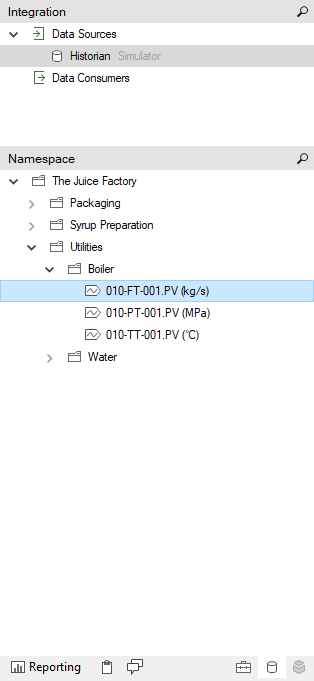
The Namespace also provides a place where you can create your own custom folders and items. You can use this functionality to create “shortcuts” to your favorite tags, or “templates” or tags that would simplify the creation of new measures (e.g. SQL query template when using the Microsoft SQL Data Source).