It is important to understand the various components that make up the Flow Information Platform. A Flow system can be deployed to a single machine (host). However, the components of Flow have been designed to work together across multiple machines where required. This architecture allows for large systems to be distributed for redundancy and load-balancing. The following diagrams shows possible architecture deployments:
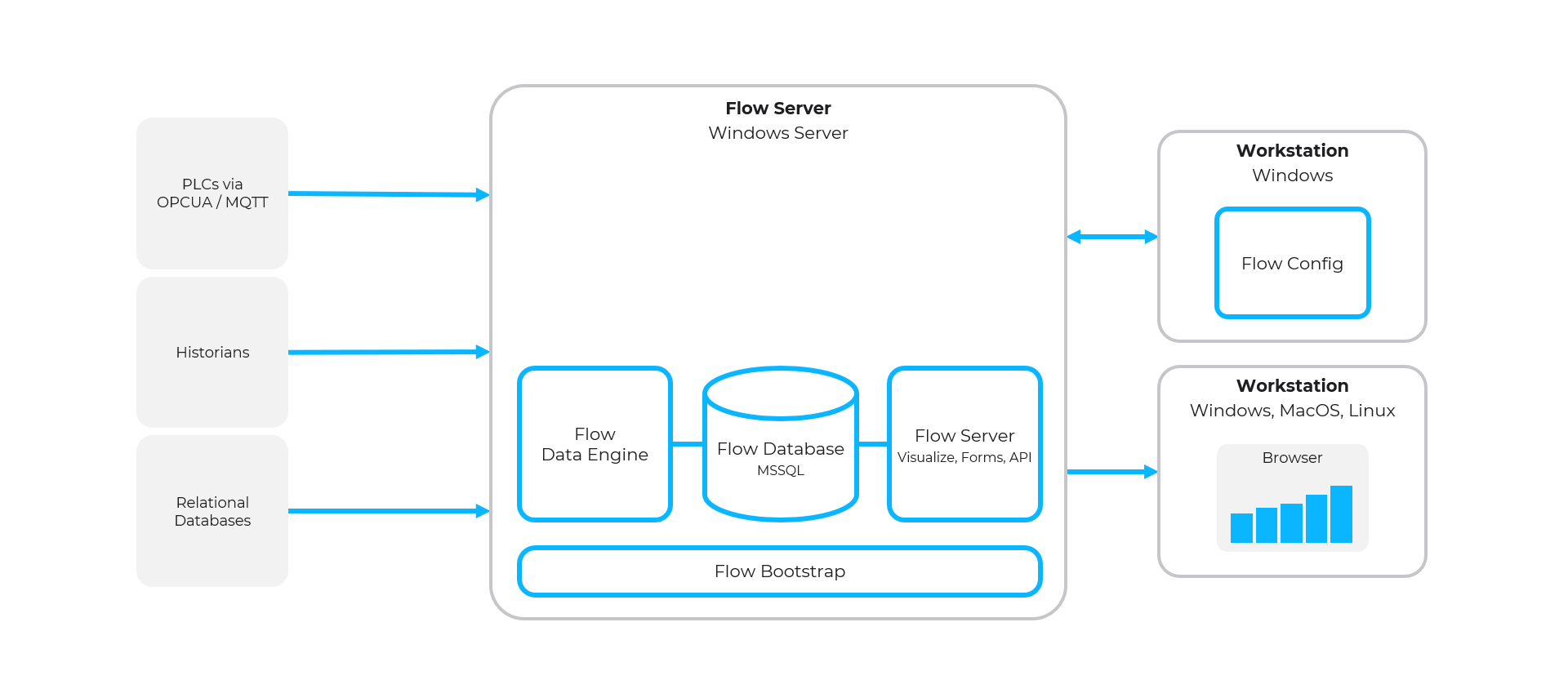
Simple Flow Architecture
- Single on-premise Flow Server including Microsoft SQL Server
- Connected to multiple data sources including PLCs, Historians, and SQL databases
- Workstations running Flow Config and Visualization via browsers
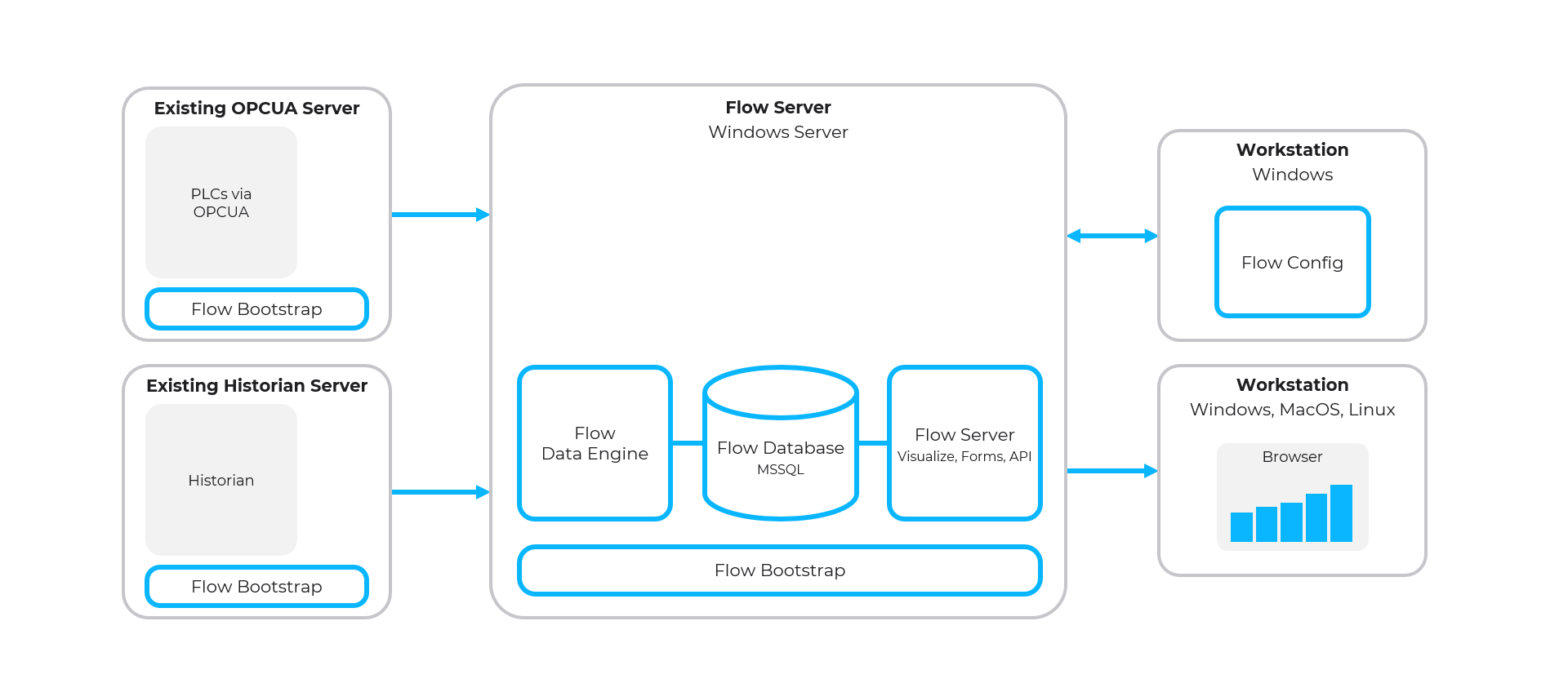
Simple Flow Architecture with Deployed Data Sources
- Single on-premise Flow Server including Microsoft SQL Server
- Connected to deployed data sources to ensure collection is local to source
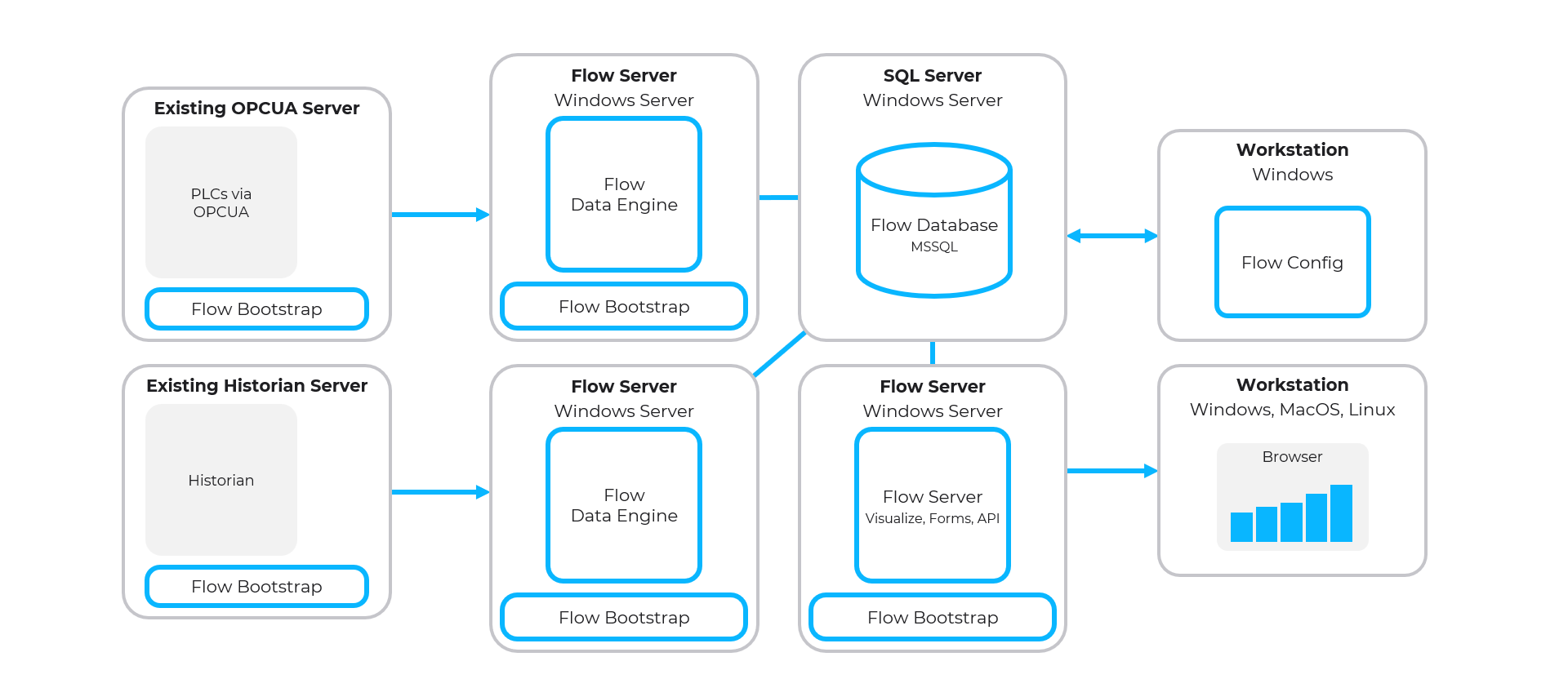
Distributed Flow Architecture
- Multiple Flow Servers to distribute computing load
- Dedicated Microsoft SQL Server
- Recommended for large Flow implementations
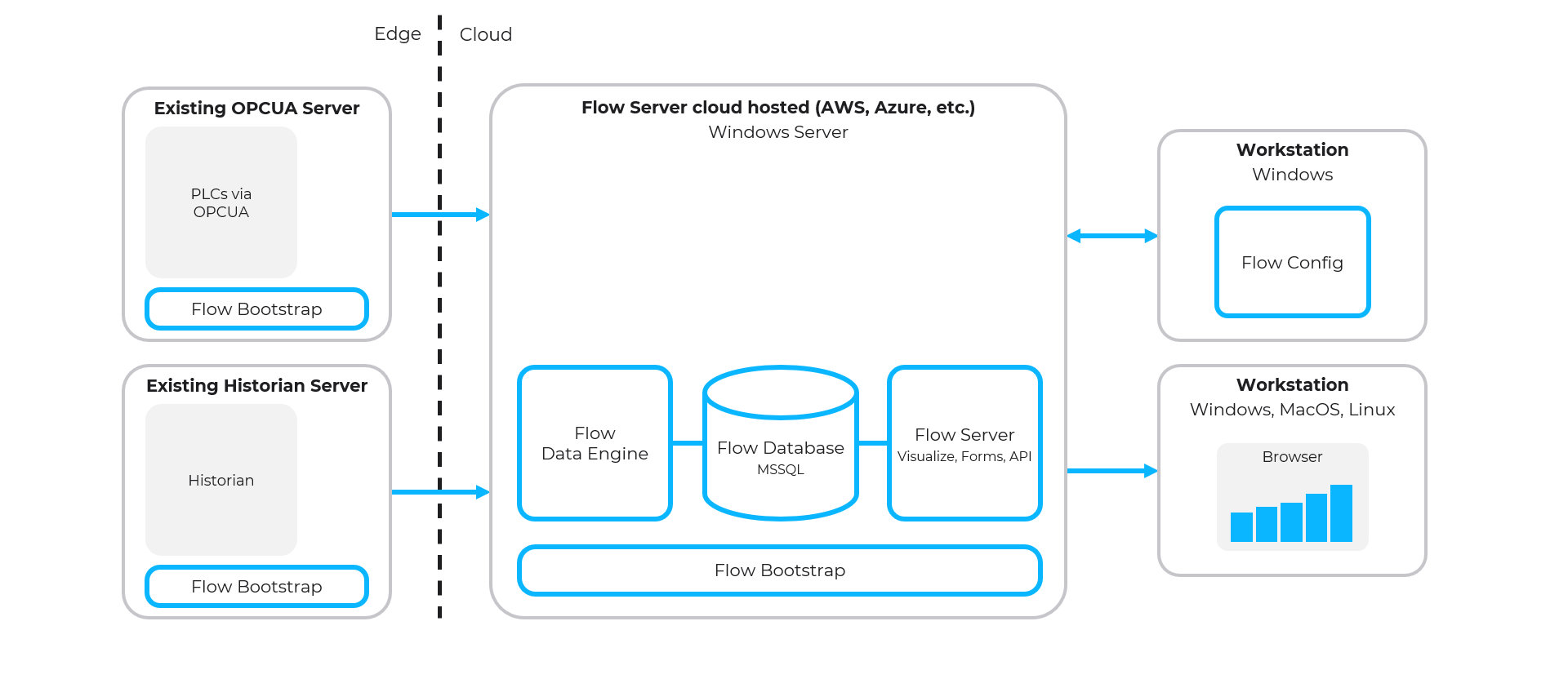
Edge and Cloud Flow Architecture
- Flow Server deployed to cloud provider (AWS, Azure, etc.)
- Data Sources deployed to edge (on-premise) using a single outbound connection
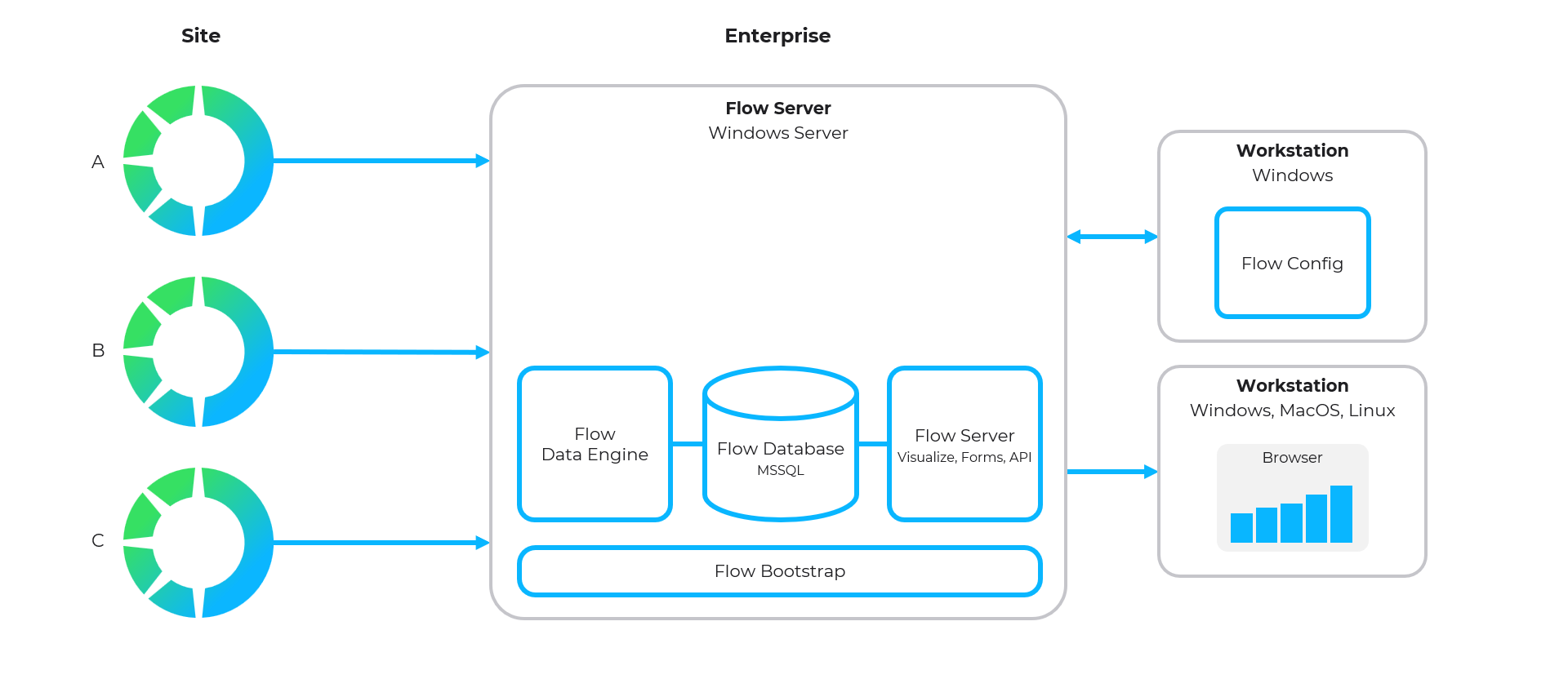
Enterprise Flow Architecture
- Enterprise rollup from multiple site Flow systems (benchmarking, comparison, planning, etc.)
- Central template management
Installed Components
Flow Bootstrap
The Flow Bootstrap is installed as a Windows Service on each machine in the distributed architecture. It is responsible for communication with Flow Config as well as coordinating the startup and shutdown of the Flow Platforms.
All Flow components communicate with each other over a TCP/IP port, namely, the Bootstrap Port. This is port 4501 by default but can be configured differently if required. It is important that the required firewall settings are configured on each machine in the architecture to allow for this communication to take place. To change port 4501 to another port, see How do I change the default port that Flow components use to communicate with each other?.
Flow Config
The Flow Config tool is the configuration environment used to build a Flow System. It can be installed on workstations or laptops that have access to the Flow Bootstrap machines. It is used to create and configure events, measures, calculations, forms, charts, dashboards, etc. It is also used to manage and deploy the various Flow components according to the required system architecture.
Microsoft SQL Server
The Flow Information Platform requires a Microsoft SQL Server installation to serve the Flow Database. The Microsoft SQL Server edition installed, depends on the Flow license size and number of years of data to be stored in the Flow System. Note that the Microsoft SQL Server installation files are not included with the Flow Information Platform installation files.
Deployed Components
Flow Database
The Flow Database is used to structure, store and index the Flow System's configuration and data. The Flow System will automatically maintain its database (i.e. index rebuilding, etc.) but note that Flow Database backups and disaster recovery procedures remain the responsibility of licensee.
Flow Platform
The Flow Platform is responsible for the startup, management and communication of components deployed to it (e.g. Flow Engines, etc.)
Flow Engines
Data Engine
The Flow Data Engine is the primary data collection, calculation, aggregation and evaluation component of a Flow System. More than one Data Engine can be deployed in a Flow System for load-balancing purposes. Data Engines are responsible for the following:
- Creating time periods against which data is collected, calculated and aggregated. These time periods are generated according to the Flow calendar definitions. For more information on configuring Flow calendars, see How Do I Configure My Calendar In Flow?.
- Accessing configured Data Sources to automatically query and retrieve information from other systems. For more information on available Data Sources, see Retrieving data into Flow.
- Performing “rollup” aggregations.
- Performing calculations.
- Evaluating information against targets or limits.
- Generating event periods based on data retrieved from other systems via the Data Sources.
- Collecting attribute information (e.g. product, batch, shift team, work order, etc.) relating to event periods in order to provide additional context.
Message Engine
The Flow Message Engine is the primary notification component of a Flow System. It will automatically package and send any messages that are configured. Once a message is packaged by the Message Engine, it is passed on to a Notification Service (e.g. email, SMS, Slack, Flow Mobile, etc.) for distribution to it configured recipients. A message can contain a combination of Flow KPI information as well as charts and dashboards. Flow Mobile is a Notification Service built specifically for users to receive information via their mobile devices, either iOS or Android. For more information on available Notification Services, see Notification Services.
Integration Engine
The Flow Integration Engine is the primary integration component of a Flow System. It is used to automatically push Flow information into other systems via Flow Data Consumers (e.g. SQL, MQTT, Flow, etc.). The Integration Engine can be used, as an example, to send Flow KPI information up to an ERP System, or even down to a SCADA System. For more information on the available Data Consumers, see What is a Flow Data Consumer?
Flow Server
The Flow Server is the primary user portal component of a Flow System. It is used to serve data visualization and analytics to Flow users via web browsers. It is used to serve Flow Forms to users via web browsers to enable the manual entry of data into a Flow System. For more information on the Flow Server, see What does the Flow Server do?