In an organization with multiple sites and a head office, it might be imperative to report to head office on the KPI and measures collected and calculated on a site level. Each site requires autonomy when it comes to its own production-focussed reporting requirements; at the same time, head office required selected data points to be replicated to their Flow system for benchmarking and comparison requirements.
This concept can also be extended to “Business-to-Business” integration. Thus, two separate companies each having a Flow system can “share” information between one another.
Think of the benefits of this type of integration in the example of a Consumer/Supplier situation; one can streamline the supply chain between the two parties by continuously keeping the supplier informed as to raw material requirements, based on current production trends.
Not only does the “tiering” technology allow for the replication of data, but it can also be utilized for template distribution and template management.

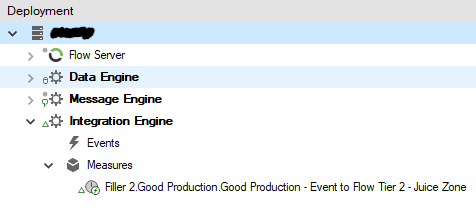
Configuring a Flow Tier 2 Consumer
To create a connection to the Flow Consumer, right-click on Data Consumers to add a new Consumer. Select “New", "Flow Software”, and then "Flow".
Select The “Flow” consumer to open its editor:
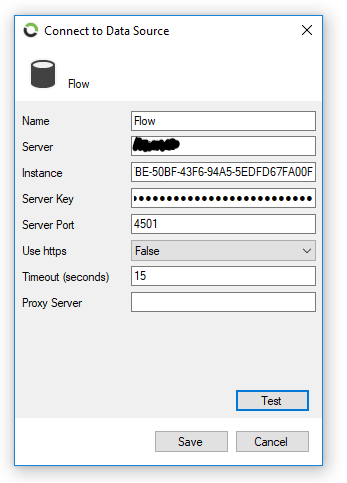
To successfully push data to a Flow Tier 2 Consumer, the following properties need to be set.
|
Name to identify the consumer. |
|
Location of the destination Flow Server (Server Name or IP Address). |
|
Instance ID of the destination Flow system to which information needs to be pushed. |
|
Server Key of the destination Flow Server. |
|
Port of the configured Flow Server, default 4501. |
|
Select "True" if the https protocol is required when communicating with the Tier 2 Flow system. The default setting is false, which means that the http protocol will be used. |
|
Time allowed to connect and retrieve the destination Flow instance's namespace. The default is 15 seconds. |
|
Configure this setting if your network configuration requires you to communicate through a proxy server. |
|
If required, specify the Proxy server’s port. Only visible if a Proxy Server was specified. |
|
Specify if the proxy server needs authentication. Only visible if a Proxy Server was specified. |
|
Specific username if proxy authentication is required. Only visible if a Proxy Server was specified. |
|
Specific password if proxy authentication is required. Only visible if a Proxy Server was specified. |
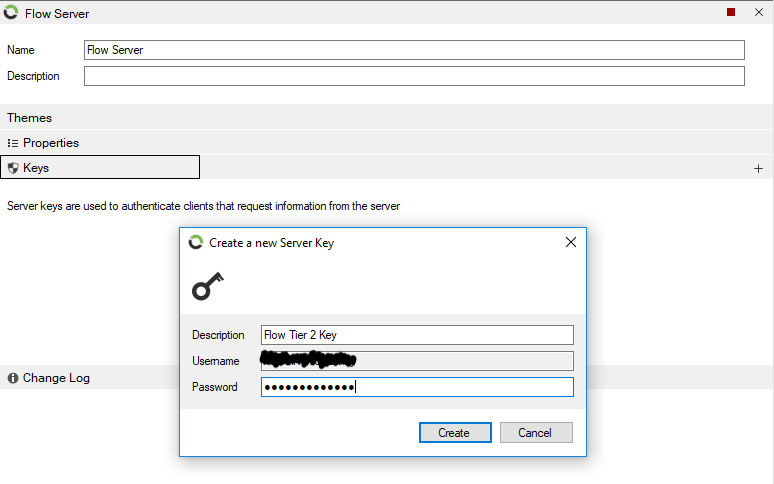
After configuring the properties, test the connection by pressing the “Test” button. If successful, a pop-up will confirm your connection or display an error message describing the issue that needs to be rectified.
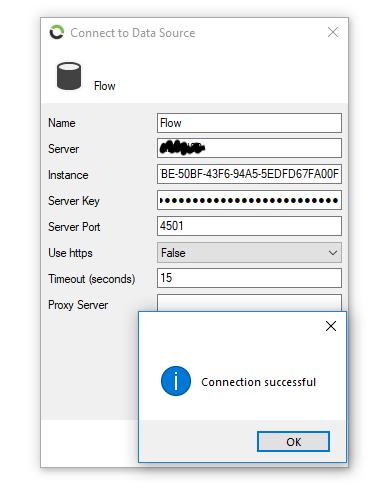
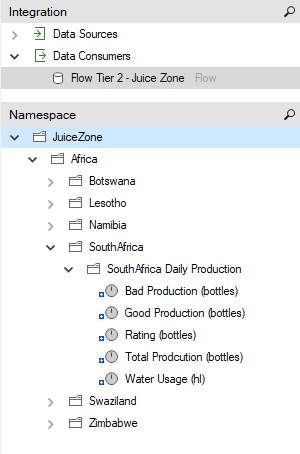
If the connection is successful, the namespace of the destination Flow Instance will be populated:
Configure a Measure to Replicate
From your Flow model, select and open the configuration for a measure that you want to replicate to your Tier 2 Flow system. The interval type of the measure must match the interval type of the Tier 2 measure (e.g. you can replicate a daily measure from your Tier 1 system to a daily measure in your Tier 2 system).
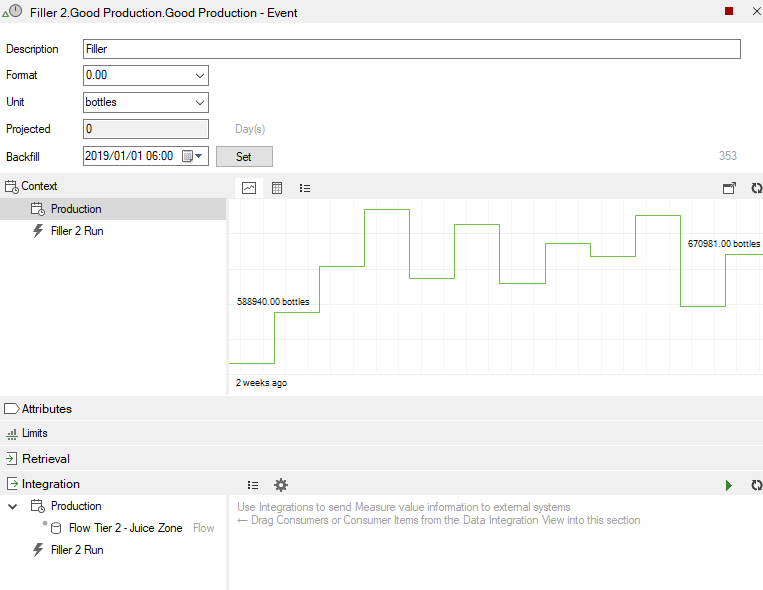
Notice the "Integration" tab in the measure configuration editor. Select the Integration tab to expand its configuration.
You will notice that any context added to the measure will be available to replicate - this includes both calendar and event context, as seen in the previous image.
Simply drag the measure from the Data Consumer Namespace onto the context type you would like to replicate.
Notice the "Properties" and "Deployment" icons in the integration section.

The Properties tab will contain the information of the destination measure, displaying its Hierarchical Name in the Measure Name text box, Measure ID and the Time Scheme selected that will be used to push the data to.
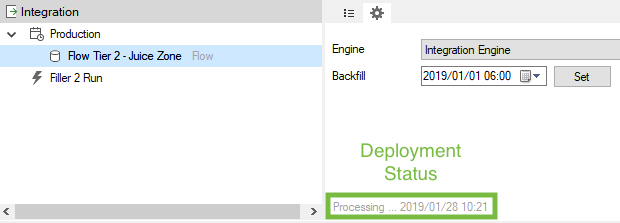
On the deployment tab, the specific integration engine can be selected that should be utilized to perform the integration task. By default, there will be only one Integration Engine.

Only in a large, distributed system architecture, will more than one Integration Engine be required for load balancing.
You can select a backfill date from which to “push” data (i.e. historical data) to the Tier 2 Flow system.

Deploy/Activate the integration to start replicating data, by clicking on the green Deploy icon in the top-right of the Integration Tab.
Notice that, at the bottom of the deployment section, there is a description of the current status of the integration, showing whether it is deployed, busy backfilling, or in a normal operation (if the integration is up-to-date and waiting for the next time period to push data, the status will display something like "Processing ..." and the date and time of the last successful replication.
If you go to your Tier 2 Flow instance, you will notice the same data being populated and displayed in the relevant replicated measure:
The Retrieval section of the replicated measure will be updated with the source measure’s details as well as the last time a value was updated/processed.

All measures configured for integration will be listed in the deployment view under the integration engine (on the Tier 1 Flow Instance)