In order to understand why time synchronization is so important between the different nodes in a Flow deployment and the data sources Flow will utilize to query data from, We need to understand 2 concepts Flow uses to manage data collection:
- Data aggregation - What happens in a time slice?
- Refresh Offset - What is this property on a measure?
Data Aggregation
Lets look at a counter retrieval as an example. We what to know the total value of a totalizer for a time period of 06:00 am to 07:00 am.
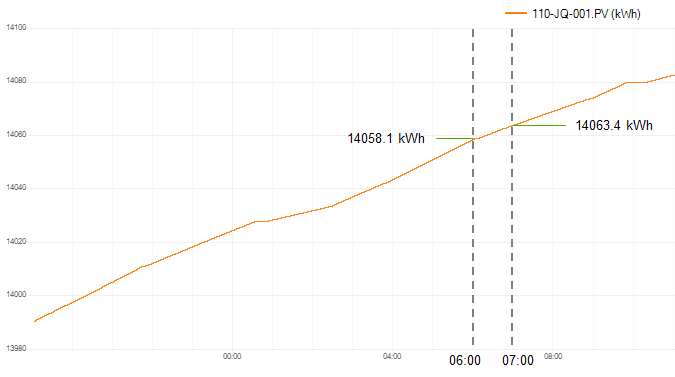
It is important to notice that there is a value for exactly 06:00 am and 07:00 am. Flow will subtract these two values to determine the total.
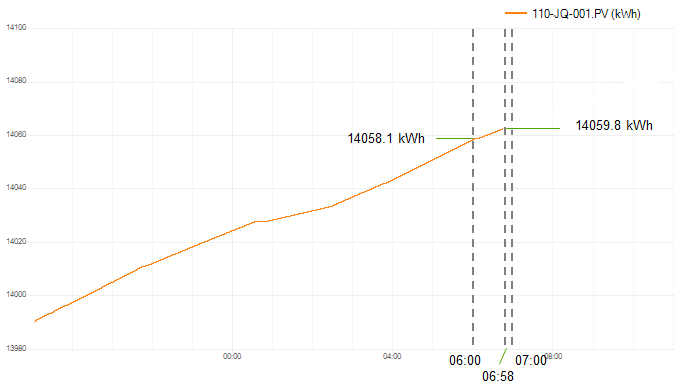
No lets look at a example where the Historian lags the Flow server from a timing perspective. In the example below, there is a value a 06:00 am, but not for 07:00 am. Thus Flow will uses the latest value available, 06:58 am instead of a value at 07:00 am.
In this case the value will be less that the actual correct value!
Refresh Offset
Flow has a set of defualt refresh ofsets that can be configured on every measure. In our example, for an hourly measure, the default offset will be 60 seconds:
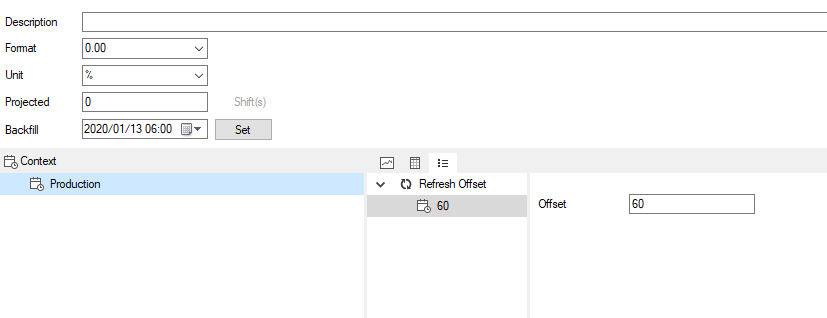
This will force the engine to wait 60 seconds before applying the aggregation method on the raw data. This can be extended. It is not a best practice way to fix time synchronization!.
All nodes in the architecture time's must be synchronized as best practice.